[This is a very first part of an article / white paper under development, just to float the idea and get response …(?)]
When asked what parts, or areas, information security would have to cover, people often respond with something in the line of ‘People, Process, Technology’ as a failed alliteration.
The Process and Technology parts are then elaborated to the point/gray area where they will have become completely stifling business, with a panicked compliance craze because of a serious mental condition being a lack of ability to accept that one cannot perfectly control everything. Which is a fact. And read, and re-read, Bruce Schneier’s Liars and Outliers over and over again till you get it.
Yes, for Technology, we do get that it’s an arms’ race against the most (more than us) skilled and sophisticated attackers. But somehow we don’t accept, and still think we can do all security upfront, ex-ante, preventative. The budget (grossly) wasted on this side, are direly needed at the other side(s), detective and corrective security. Or rather, the money would be much, much, much better spent there. Sid vis pacem, para bellum preparat. We’ve only just started to learn how to do that properly.
Since for the most part, we’ve focused on Process. To death… Figuratively, almost literally. We’ve designed way too much top-down analytical procedures, that result in infeasible requirements and lots of babble at the shop-floor level where the front line is. Don’t even start me on ‘three lines of defense’ that are a lot but not defense (i.e., they simply do not between any threat and any vulnerability!), don’t start me on ISO27kx compliance either. Oh, compliance, the killer of anything alive, the H-bomb of actual (sic) productivity, revenue growth and cost savings.
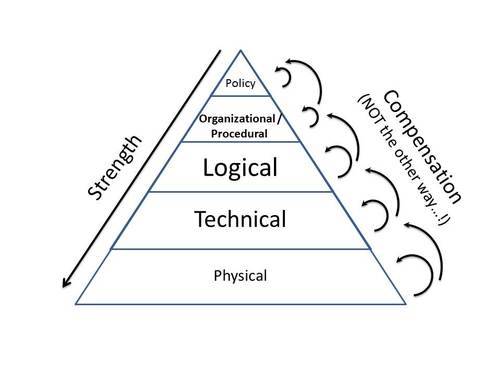
How did we get there ..? Simple, by not understanding that Process and Technology are just two parts of the formal structure of infosec. And as in the picture, we have almost forgotten that information security is a stacked thing.
Physical security sits at the bottom, at the base, often much underestimated in its importance.
Next comes technical security, ranging from sound architecture (not the usual goalless kind, but the one focused at lean and mean design including e.g., privacy by design/default, all the way via OS security, middleware security, application security and communications security. The parts that you don’t ‘see’ I mean, the hardware, the software, the parameter settings.
Then, there’s logical security. The kind you know, that sounds very abstract, almost philosophical but all we know about it is that it’s about password strenght and the failures (sic) of RBAC and such.
One step higher up, and again failing one order of magnitude more!, is organizational security with all its processes and procedures. How blithely stupid the rules are, and how completely and utterly they fail to contribute to security and fail to fix lower-level shortcomings, as they should.
At the top of the pyramid sits Policy, to ward off te evil forces of the babblefolk. Much to be said about this (level), which feeds the desires of those that have fled into a narcissist self-inflation fleeing forward from a lack of self-confidence and a fear of being called out for emptiness of understanding. Much will be said; elsewhere.
And, as in the picture: To understand it, one should understand that the lower the security controls, the harder they are; tougher, more resistant against attacks of any nature. The higher up, the less is contributed anyway. Bable, babble, that is what most is. Ever seen a policy statement line that actually protects against even just one Advanced Persistent Threat ..?
As is also in the picture, lower-level controls may very well cover for either control failure (lck of suitable control(s), or failure of control(s)) at the same or higher level, but a higher-level control can NOT compensate for a failure (of presence or of quality) of lower-lvel controls. But this is what the great many in the field think is the common, all too easy solution ..! Compensate up ..! Which will fail ..! At least in a house of cards, the upper cards are similar in quality to the lower ones. But the lower ones will carry the higher ones, and if a lower one tumbles, the higher ones come down. Would you suggest that if a lower-level card would be / get missing, the higher cards in the house of cards would keep the whole thing standing …!?!? If so, you would really be eligable for a guided living program.
And the picture is far from complete. Remember that above, we started with People? Where are they now, then? Where are they in your information security posture? Ah, you have awareness campaigns. Right. Haha. Oh, thought you were joking.
The ‘joke’ of the thing is that People are everywhere in the picture. Not only within te triangle, but also, vastly more so, outside it. If you implement any tinesy part of the triangle in a way that hinders co(sic)workers to achieve their objectives, they will obliterate your controls. Information security is Overhead!
And People are threats, yes indeed, but they’re also Physical, Technical, Logical (their logic, not yours!) and Organizational assets, vulnerable at the same time. Vulnerable asset and controls in ‘one’, of a wide variety.
Well, you can understand that, as we haven’t dealt with People almost since the inception of information security as an IT thing – since as an IT thing, it has grown within the formal triangle – we hardly understand a thing of how that people part works. We do in a sense, we do have psychological sciences (admit it, working in another Kuhn/Lakatos paradigm but undeniably (partially…; ed.) science). But information security practitioners don’t understand humanity. Infosec practitioners are engineers, seeing the next problem in their hands only (hardly even one ahead) and trying to fix it as quickly and pervasively as possible, and then move on. Whereas the humanities side of life is beyond them. As far as we (all humanity) know, human failings are of all times, recognised throughout the centuries, and still unfixed. We still dream of being (more) civilised than our ancestors; wrongly so! But we have to deal with those sides of People in particular now, for information security.
…
I’ll just stop here. You can see that so much, much more can be written, and should in my opinion.
Do I state that one wouldn’t need all the formal controls? No. But I do mean that a lot of what we have today is rubbish. [Disclaimer: This is not a statement that my current employer is or is not better or worse than average, but they certainly hinted some catharsis and solution content of this column and white paper (to come).] Incomplete, inconsistent, failing wholesale as we speak. We need much better, meaner (and if we achieve that, leaner) infosec controls. And much more of them, outside of the traditional boundaries.
So there you have it; the inception of an idea that will be discussed at great length as you know I can, in a white paper to be published somewhere, sometime in the coming months. Please feel free to comment and add already. I’ll keep you posted!

 [Toronto, but you knew that]
[Toronto, but you knew that] “Never trust any statistic that you haven’t forged yourself” as Winston Churchill put it.
“Never trust any statistic that you haven’t forged yourself” as Winston Churchill put it.