
[From Riga, for you]
For a real update on my Prediction for 2014 (see below some post, and the original post), I homage Ross Dawson for a much better long-term rationale.

Mostly on wine. Also: IRM/InfoSec/I-Advisory and -Audit services. Positive contrarian, inspirator, loosen-upper.
[From Riga, for you]
For a real update on my Prediction for 2014 (see below some post, and the original post), I homage Ross Dawson for a much better long-term rationale.

[Unseen Rotjeknor]
In the stories on Big Data et al. (predictive analysis, … , you name it), I often see a big confusion about terms. Some even mix up data and information, or only pay lip service to the fundamental difference..!
Oh yes, many come up with the Information Pyramid; in a most basic picture I took from wipo.int:
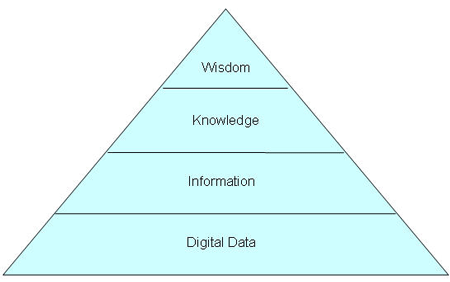
* sometimes, Knowledge is bracketed between Data and Information; more on that below.
But there’s something fishy with the way the picture is being used, commonly.
For one thing, any action that produces meta data (i.e., just plain flat derivative data !!) is considered to be ‘enrichment’ onto Information. But that’s wrong! All the aggregation, the averaging, the abstraction that you do, only delivers other data, with the (near-mathematical) translation functions still intact – although also, information gets lost..! Yes, the details count, and have their own ‘information’; a full description of all data points in a set would require at least all the data points themselves, or miss something when they’re described, circumscribed otherwise.
The problem is; no-one really knows how to get from Data to Information as we intuitively (heh) understand it. Information seems to be detached, or separated from Data by a chasm that we do not know how to cross, probably because our understanding of what Information is, and our definitions, are so weak.
Oh, and putting a layer of Knowledge in between Data and Information, doesn’t help anything, either. Even worsens the problem. As it is above, it doesn’t say much either. And instead of Knowledge, above one could also fill in Understanding, or Insight (which would come closer to but remain separated from Wisdom). And above the peak, is there Nirvana? Smells like blog spirit.
So, all the efforts of NLIQ and MITIQ may be fine, as for data analysis to try to achieve predictive analysis (nice pun, the contradictio in those terms!), but as long as Data and Information are used arbitrarily (see the list of publications and the actual articles contents …), one will remain stuck in data analysis and not reach the next level of Information. Or Knowledge, let alone Understanding, Insight or even Wisdom.
But I keep running in circles. Yes, I know, and I also know that in order to advance, we’ll need to get a grip on two things:
1. Definitions, in the traditional sense or by way of aspect/category/label/hermeneutic quality descriptions, of all the levels we may distinguish;
2. Definitions, in both ways, too, of the transitions and transition methods, tools, etc., we may construct theoretically and practically.
I’ll do some work on this, but your help is appreciated..!

[Antwerp. Seriously.]
In some previous post, I posited that we should move from quantitative (quod non) to qualitative or even intuitive risk management.
And how that may be difficult. ‘cause it is.
As an intermediary step, I propose to build a better language with which to communicate, discuss and calculate (sic) with qualitative risk management.
Because I see a place for a combination of fuzzy logic and wavelet theory, including neural network signal combination functions.
As my time is limited, this time of year, would anyone have pointers to what’s already out there in papers, practical applications, etc..? That could kickstart the discussion. And I’ll return with more, better, more extensive, more thought out stuff on the subject later.

[Guess the location]
Your digital ID becomes your pseudo-identity becomes who you are (considered to be), more than your actual you.
Your actual you, your innate identity, the one you discovered when only a couple of years old, will no longer be of interest to the world once your digital identity has all that the world cares about. Then, it can get stolen, lost, manipulated and altered, without you actually needing to notice. But who cares? Your digital ID is, you are just the carbon-based remnants of an outdated world. Just make sure there’s a fallback scenario that you can (or wouldn’t need to) prove you are you, your digital ID isn’t you.
The singularity may do away with you because you only use up scarce resource. You are not productive, your digital identity is. So you should care. Or?
If social media use ‘you’ as a resource, uses your apparent digital ID (ID and all posts, tweets, etc., turned into a persona, sold to all bidders) to operate, can you not deploy some artificial intelligence mechanism to do the socmed postings on your behalf ..? What’s the difference to the socmed companies that not your brain, but an artificial brain is used ..? Or do they already have their own farms of AI personas, to beef up traffic and sellable ‘user’ generated content ..?
Their AI personas may create a world separate from yours, a virtual world where they make money, not needing actual users anymore.
Your personal self may deploy AI to detach from their abusive, you-usurping world.
Case closed?

In the discussions re privacy, there seems to be only two alternatives: Absolute privacy, with any individual holding complete, total and continuous control over who gets to see (not take in) any data point that may be, even in the remotest of ways, be recombined into anything useful for anyone – or Absolutely no privacy, everything being considered lost anyway and all one’s data being out there somewhere.
Which creates not some binary future state, but a bandwidth on which we should be able to choose. Because it is not privacy that people are concerned about, but the loss of control once data slips out of your hands. That is why everyone is so concerned when TLAs are found out to collect so much data on everyone (they have tried, and partially succeeeded, already for decades; nottoo many people were concerned) or when (not if) yet another credit card data processor looses some backup tapes. It is not the privacy in itself (one passes off the credit card number (and CVC) happily to just any unchecked device), it is not being able to get the data ‘back’, not being able to track the use in all the enormous amount of systems one knows is out there handling your data. Those systems ranging all the way from the benign to the crooked, always …
What we should have, then, is some mechanism by which we would be able to transparently and trasitively (sic) release the data we must (in order to get some service in return), and be rewarded for any data other parties earn money with (they are using your resource!), and not more. We’ll have control back; all we wanted.
Anything else, and we’ll end up in one of both extremes. To our own extreme detriment.

[Educational institute x 3, campus Free University, Amsterdam]
When sleeping over problems, one often comes up with solutions that both are real and so all-encompassing that they’ll need much elaboration before being applicable in a nimble way.
This one was/is on information security, again. Recall the ‘discussions’ I posted some days ago about (industrial) process control versus administrative control? Well, I’ve some more elements for a grand new scheme now.
It struck me that the operators at the (chemical) plant control room, are the ones with the dashboards. Not necessarily their managers. Nor their manager managers, etc. What if instead of some machine equipment, we plug in hoomans into the whole ..? And let them interact like the übercomplex ‘machines’ that they are, doing their (administrative / service) thing that they (want to?) do. All the way to the point where we have no equipment, just humans (with tools, by the way, but those would be under ‘complete’ control of the ones using them so are just extensions of them). One ‘manager’ could then control quite a lot; have a huge span of control…
If, big if, if only the manager would understand the overall ‘process’ well enough, that is, to be able to work with the dashboard then provided. Just Continuous Monitoring as a job, not much more (one would have 2nd- and/or 3rd ‘lines of control’ (ugh for the expression) to fix deviations, do planned maintenance, etc.). Probably not. But one can still dream; organizations would be flat without chaos breaking out.
And if you’d say it would be impossible altogether, have a look at your SOC/NOC room where techies monitor IT network traffic and systems’ health. They even have some room to correct..! And they are aware, monitor, the appropriateness of what flows over the lines, having professional pride in catching un(machine)detected patterns of irregularity possibly being break-in/break-out attempts. And they leave the content for what it is, that’s for the experts, the users themselves, to understand and monitor if only they would.
Why wouldn’t other ‘managers’ copy the idea to their own desk? No, they don’t, yet. They get Reports that they hardly read, because someone else had thought for them in determining what should be in there. And reports aren’t continuous. Walking around is, but would (rightly) be viewed as micromanagement and a bit too much given the non-continuous nature of what modern knowledge workers do. So, we’ll have to define some gauges that are monitored semi-continuously.
Now, a picture again to refresh:

[Westpunt, Curaçao]
But with the measurements not influencing the primary production ..! To let knowledge workers do their thing, in mutual cooperation without interference by some busybody thinking (s)he knows better for no reason whatsoever.
Through which we note that the use of dashboards should not, must not, start with ‘Board’s or similar utterly superfluous governance levels. Governance is for governments. As it is ‘implemented’ in larger organizations, it doesn’t look like kindergarten kids playing Important for nothing. The use of dashboards should start from the bottom, and should include quite rigorous (but not merely by the numbers) pruning of both middle-level ‘managers’ (keep the good ones, i.e., not the ones that are only expert in hanging on! otherwise you spell death), and all sorts of groupie secondary and third-line staff.
Which will only work if you haven’t yet driven out all the knowledge workers by dumbing down their work into ‘processes’ and ‘procedures’ that are bereft of any productive (sic) rationale. And if you haven’t driven out all the actual managers and are left with the deadwood that is expert only in toeing the line or rather, sitting dead still in their place.
Now have a look back also on how you do information security. Wouldn’t the little bit of tuning you may need to do, be focused best on the very shop floor level that go into the ‘industrial’ process as inputs? You would only have to informationsecure anything that would not be controlled ‘automatically’, innate in the humans that handle the information (and data; we’ll discuss later). Leave infosec mostly with them, with support concentrated at an infosec department maybe, and have managers monitor it only to the extent necessary.
And, by extension, the same would go for risk management altogether. Wouldn’t this deliver a much more lean and mean org structure than the top-down approaches that lead to such massive counterproductive overhead as we see today? With the very first-line staff that would need all the freedom feasible to be productive (the managers and rest of the overhead, aren’t, very very maybe only indirectly but certainly not worth their current income levels!) then not having to prove their innocence… See Menno Lanting’s blog for details…
Org structures have become more diamond- than pyramid-shaped; which is plain wrong for effectiveness and efficiency…
So let’s cut the cr.p and manage the interfaces, vertically, and horizontally, noting the faces part; human. An art maybe, but better than the current nonsense…
Already somewhere below, I noted that the Analytics part of SMAC(T) may need to be rephrased. Already now, I’m unsure whether to do that or just leave it unchanged. What I didn’t yet do, was to opine on the other elements so often put together.
First, a picture.

[Casa de Música Porto, for the chaotic structure of the future]
Now then:
Social everything: Yeah, yeah, of course there will be news. The decline of Fubbuck, etc. But will we see actual breakthrough hitherto unseen inventions of anything game-changingly new? I predict 2014 will be a pause year in which we’ll only see paradigm detailing and quite an improvement (sic) of the use of Social by medium- and larger sized enterprises. In somewhat innnovative ways, but nothing earth-shattering.
Mobile everything: The same, hopefully through the much-wanted huge improvements in cross-platform and cross-screensize compatibility and standardization. Which, too, would be refinement rather than absolutely unexpected New.
Analytics, we discussed, separately.
Cloud, ‘mehhh’ for theory, ‘hey how refreshing to be able to distinguish so clearly a good implementation’ in practice. Because that’s what we’ll see in 2014; cloud stuff deliberately done right. (Being deliberate, not by accident as it was in 2013!)
Things; The Internet Of ~, maybe, but in my view it’ll be too early. More like something for under the [Warning: European + derivative culture reference coming up] Christmas tree, to be played with in the year after.
Any other business?
Yes.
One with long odds: Clarity on the demise of “ERP” software. Of course, pre-2014 already the said administrative software, hardly ever used to its full potential but very often having been relegated into the bookkeeping role only, had been pushed away from the limelight into the back of the stage. But in 2014, we’ll see an acknowledgement of this, with consequences I cannot really predict very well – probably, all sorts of other software, more geared towards front-office functionality and integrating better architecturally with the bandwidth from there to the app/widget-world, will take over center stage.
[Update 2014 02 06: This link]
One with lesser odds: An enormous push for more information security, both at its operational, technical levels and upwards in renewal of structure (away from the stale, outdated ISO2700x sphere!) and inclusion of a more holistic approach (see some of my earlier posts, and probably some to come in the near future).
This will have a second leg in renewed interest in Business Continuity Management, not only by rule-based following of standards but also by more principle-based (sic) implementation of ISO 31000 (with all its drawbacks) throughout the business. If we can get our heads around the eradication of that ‘the business’ nonsense… and really integrate (continuity) risk-based management into general management, not needing too much 2nd or 3rd lines:
A final one: The deflation of TLD. The three lines don’t actually defend against anything but regulatory discovery of all that goes wrong in the business (from top to bottom and back again, there). As the previous prediction will already defend against actual mishaps, TLD will be shown to be emperor’s new clothes where lightning strikes. And oh will it strike; frappez, frappez toujours! it will and I hope. All those busybodies doing busywork, I just can’t stand it. The utter denouncement of humanity and human dignity …!
So, there you have it again; SMAC(T) weighed, and three more. Who make some interesting stuff available when I hit (or overshoot) five or more out of eight ..?
To close, another picture…

[Serralves, Porto – rainy outlook]
Before I forget: Some work has been done indeed on translating the industrial process (control) model to the administrative world. ACS’s KAD+ model (in Dutch) is an excellent example – especially the original KAD model at operational level that seems unsupported now. Maybe they are just a bit too far ahead of the curve, too clean-cut, to have found the traction they deserve.
That’s all, folks!
For now. Here’s a picture for your viewing pleasure:

[Alhambra, Granada]
Yeah, next up, some seriously long form blog again.

[Unfamiliarly, from the West]
The end is nigh, of 2013. Can we predict what the big business / infosec hype of 2014 will be ..?
No. There’s no predicting the unknown. The somewhat-known will not stand out enough. The known… boring!
The knows are the fall of Fubbuck, maybe Tvitter (both to be replaced by the WeChat’s and hopefully Tumblr’s of this world; will Vine and Snapchat take over?), cloud, BYOD/flexwork, etc.
SMAC: Social, Mobile, Analytics, Cloud. ViNT by Sogeti adds a T of Things.
The Things part, I’m unsure about. Yes, for the long run (i.e., 2-5 years) we will definitely see an explosion. But next year already? It’s the infancy of a sine wave, taking off slowly.
So, my prediction is that the thing we’ll all be talking about as the next thing in 2014, would be … People versus Algorithms.
This was pointed out by some #Coney guy(s), with some lead links elsewhere. But algorithms will not conquer the world in one swallow. Rather, we will see both an increase in the use of algorithms for partial (at most!) data analytics, to support TLA-style use of ‘big’ data both in public and private environments – but also a major development of the People component in tha analysis, a wave of development of specialized functions, methodology and tools, re the human pattern detection and interpretation parts of analytics.
Plus, then a more clear picture of how people and algorithms fit together, as function, profession(s), etc., with spin-off everywhere e.g., the development of a better understanding of how the brain works, how humans work (produce / operate), how to describe the purpose of life. On our way to the Singularity, and Beyond!
Just a question: Would anyone know some definitive source, or pointers, to discussions either formal or informal, on the logic behind double secrets i.e. situations where it is a secret that some secret exists ..?
Yerah, it’s relevant in particular now that some countries’ government seems to have failed to keep that double secret completely, but should be more systematically dealt with, I think, also re regular business-to-business (and -to-consumer) interactions.
So, if you have some neat write-ups of formal logic systems approaches, I’d be grateful. TIA!

Voor sigaren bepalen we het profiel aan de hand van de criteria Smaak, Balans, Body, Sterkte, Aroma en Finish.
Voor Smaak pakken we het aromawiel erbij. Let wel I; wat u proeft of verwacht, kan gedurende de diverse fasen van het roken nog variëren... En let wel II; er zijn ook aspecten die nog niet zozeer als aroma staan aangegeven in het wiel, we denken aan termen als (ja de sigarenwereld is langzamerhand, helaashelaas US-, Engels geworden) zesty, tangy, floral, en earthy, of soms zelfs metallic. Lijkende termen die een combi zouden kunnen zijn van diverse aromas en papillaire en olfactorische/nasale sensaties en -tactiele invloeden. Hierbij komen termen als 'complex' uiteraard ook bijgepakt, om in dit geval te beschrijven dat er vele aromas herkenbaar zijn. Rustig roken, dat is niet alleen beschaafder en allerlei sigarenrokeneffecten-versterkend maar biedt ook meer kans om aromas te onderscheiden.
Balans is voor de hand liggend; of de zoete, zure, zoute en bittere tonen (OK, en 'umami'...) in balans zijn. Ja, ook bij een sigaar – al zal het meestal gaan over de balans tussen 'creamy' en 'spicy' en gaat het meestal mis door te veel bitter of te veel spiciness.
Body gaat over de volheid, in dit geval vooral te bepalen aan de volheid, dikte, dichtheid van de rook. Die ook een gevoel geeft; 'light' is als een licht bier, 'full-bodied' is als een rechttoe-rechtaan whisky of cognac.
Overigens hoort bij Body ook textuur, 'leathery', 'meaty', 'silky', 'creamy', 'soft', 'succulent', 'woody', 'chalky', 'dry', 'oily' en 'spicy'. Die dus net niet hetzelfde zijn als de aroma-indicatoren uit het wiel; soms overlappend. Niet handig maar zo is het nu eenmaal.
Sterkte is een wat eenvoudiger maat voor het nicotinegehalte van de sigaar. De topbladeren van een tabaksplant heeft meer nicotine dan de lagere bladeren – me(n) dunkt dat de topbladeren zijn waar de plant verder wil groeien en dus betere bescherming nodig heeft van de nico; lager is het wat ouder en 'expendible' dus ga je daar als plant niet je nico op concentreren ..? Waar de sigaar van gemaakt is, heeft dus invloed. Kan je meestal niet kiezen, maar wel proeven. Rustig roken is ook hier handig; om een nico-klap/duizel te voorkomen bij het opstaan.
Aroma dan, vervolgens. Ook hier kan het aromawiel worden ingezet. Vreemd genoeg is het moeilijk de aromas te bepalen als we zelf roken; iemand anders' rook kunnen we beter analyseren. Of we blazen de rook door de neus uit ('retrohaleren'), dan hebben we wel de volle verfijning (ga ik vanuit, lezer!) van onze neus ter beschikking. Bedenk bij het 'benoemen' overigens dat we veel meer uit ons geheugen putten, qua eten en drinken!, dan we wellicht zelf(s) denken. Dus rare smaken herkennen is niet raar.
De Finish ten slotte is kort of lang, naargelang de aromas lang op de tong (sic) blijven hangen. Milde sigaren zijn nogal eens kort – hetgeen niks zegt over de complexiteit, overigens. Hierin zit ook de reden om een zwaar (sterkte)kanon na een milde te nemen, niet andersom.
Als het gaat over de champagnes en hun profielen, pakken we er de (echte en semi-)klassieke wijn-analyses bij die we allemaal wel kennen; onderscheidend in [Hier verder. In ieder geval https://www.wijnwinewein.nl/hoe-proef-je-wijn/ en aromawiel + zuurgraad/tannines/body(viscositeit/alcohol/tannines/smaakintensiteit/mondgevoel)/afdronk + Aanzet/Zuren/Zachtheid/Tannine/Body en alcohol/Afdronk/Smaken dus de aromas bijna-los van structurele criteria. Dan de smaken matchen met die van sigaren, of niet; Klosse's overlap/contrasten erbij halen en dan verder. En toespitsen op champagnes... pak het smaak-plaatje van het CIVC erbij!]
Dear reader; bij deze dus de waarschuwing dat u vanaf hier (?, inderdaad, echt niet alleen hier) serieus te lange zinnen tegenkomt.
Ach, daar ben ik me prima van bewust, mijn hele blog is immers ook een poging tot schrijfoefening in alle facetten. Sommige posts daar blinken uit door korte zinnen en ellipsis; ook deze pagina is opgesteld als tegenwicht. En ik vertrouw erop dat u dat gewoon doorlezend aankunt.
Als voorbeeld: Oplettende lezers zullen opmerken dat onderstaande waar het uitweidingen achter links naar andere pagina's betreft wellicht beter met behulp van OnMouseOver's, alt-tekstblokken of andere tags per pop-uppable item zou kunnen zijn geïmplementeerd maar ik heb het zo gekozen en ik kan best komma's toevoegen in deze zin maar ook dat heb ik achterwege gelaten zonder de leesbaarheid of de begrijpbaarheid in het gedrang te brengen.

Inderdaad, het ontwikkelde, ik schreef, een en ander vanuit een voortdurende, voortgaande research. Na zoeken in het wilde weg algemeen, navraag bij het Comité (iv) Champagne, een aanvullend zelfzoeken met Google Satellite én Street View zowel rond de officiële als in het algemeen, kwam ik tot de Lijst Van (uiteindelijk) 84. De en passant gevonden kaarten leidden tot enige aanvulling. Toen kwam ik Weinlagen.de tegen en tsja dan ben ik niet meer te houden qua sys-te-matisch alle streken én plaatsjes af! Hoewel, ... in onderstaande tabel heb ik maar niet meer voor ieder stuks de Street View erop losgelaten of onderstaand ingevuld. Terwijl ik er vanuit ga dat dit alles nog aanvulling kan krijgen ... Les Clos Inconnus zijn uiteraard zichzelf.
De gangen kwamen al zeer onregelmatig door, en met andere tafels die uitliepen en/of (weer) bijtrokken, tot zeer ver inhalen zelfs, tot gang 6 van de 7 tachtig (schrijve: 80) minuten op zich liet wachten, ondanks diverse malen navraag. Waarna het nauwelijks-opgewarmde pompoen met koude polenta bleek te zijn; "dat hoort zo" ammehoela. Nee, het niet-koude nagerecht erna hebben we niet gehaald; we zijn opgestaan en weggegaan. Die zien ons nooit meer, zeker omdat de bediening ook Zwak was (gangen aan verkeerde tafeltjes serveren want die waren al twee gangen verder), etc. En balsimaco-saus dus, 'et al.'...
Huh, da's écht voor de Insiders..? Inmiddels wel toegestaan als aanplant, maar nog zo'n drie tot tien jaar onderweg voor er de eerste re-de-lijke wijnen van kunnen worden gemaakt en dan is het nog maar afwachten. Je weet het niet van tevoren hè, met zo'n non-Vinifera druivensoort..! En dan had je Floreal, Artaban en Vidoc nog niet gezien. Die mogen (in de toekomst) ook... En dan is het Comité Champagne ook nog bezig met kruisingen van de Top 3, Arbane, Meslier, en Gouais. #feest
En dan komt hierna een nóg spectaculairdere outsider: Chardonnay rose Rs, minder dan een kwart voetbalveldje aanplant...
Mineraliteit verdient een aparte behandeling; vanuit het idee van 'huh er zit echt geen mineraal/steen in je wijn en lik jij aan stenen-dan'-versus-'toch proef ik die sensatie en Ja' tot en met de abstracte benadering van een kennelijke associatie van een gewaarwording als hier, tot een synthese op de as 'bodem-microbiologie'-in-combinatie-met-'feitelijke chemie'. Want, jawel, fenylmethaanthiol zorgt voor vuursteen / aangestoken lucifer, in combinatie met benzaldehyde (uit 'hout') en waterstofdisulfide (uit reductie; en beide uit bepaalde gisten!) leidend tot Vuursteen-herkenning, versterkt bij anorganische ammonia bijvoorbeeld. Vuursteen is geen 'mineraliteit' maar daar wel belangrijk onderdeel van. Dus Ja, er zitten wel degelijk chemische stoffen in (niet alle gelukkig) wijn die een sensatie veroorzaken die op mineraliteit lijkt. Zout, uiteraard, ook, (niet meer maar wel) vaker dan we denken! Alles tezamen een uit-ste-ken-de reden om te spreken over herkenning van Mineraliteit in wijn. 0-10 en een penalty tegen voor de geo-logen.
Laherte Petit Meslier in the tasting round
Yes @laherteaurelien makes a monocépage of this one. Great Meslier it is:
The golden colour would suggest something dosée, but look closer and you notice a hue which points to slight bitter influences. And indeed, on the nose we get a whiff of smoke, certainly straight after the pour; quite an opportunity to use the word ‘empyreumatic’... Did I mention Meslier already? One to one it is. But nothing referring to your cooking qualities; it’s more like a distant secondhand puff of Belinda – I’d not suggest you buy that for comparison; trust me as smoker it’s trash but as Meslier aroma it’s excellent full stop. Crispy dry cigar smoke fits better.
Certainly, since this all is followed up, much more persistently, with quite some mature lemon and a whole slew of herbs and spices notes. It smells like a merry-go-round of eucalyptus, dill, thyme, spearmint, soft mint, basil, anison, verveine... wormwood even; those that know génépi, find it here, too.
The first sip jumps in with a most delicate mousse, a sensible but not too fatty mouthfeel, nicely balanced with lemon dominant in combo, and ginger/pineapple/mirabelle and dry lemon rind flipping back and forth. In the remarkably long finish, the rind does a gentle cleanse.
But I couldn’t find any cardamom that some mention, nor cocoa or coffee. All in all, in cocktail terms it would fit in the range of the French 75 and a Fleurette.
I’ve tried a little bite of camembert, but you shouldn’t. The bitter of the wine is lost but notches up in the cheese, which tastes odd. The fit with lightly aged Comté or same-Gouda is perfect, however. Sushi should work, too, if with a suitably subtle pinch of wasabi, no more – harsh coriander, algae, chervil, wasabi as such weren’t in the nose.
In summary: All of you should have a taste of this one, or one couldn’t be trusted on champagne connoisseurship.
[Degorge 12-2021, hence the progressed maturity]
Links:
https://maverisk.nl/de-forgotten-four/ for Petit Meslier
https://maverisk.nl/champ-sigaar/ on the cigar smoke angle
https://maverisk.nl/geneprima-spul-hoor/ on génépi
https://maverisk.nl/mirabelle-wil-iedereen-welle/ on mirabelle
@champagnepascalmazet make quite an interesting range of wines, fully certified bio since 1980. We tasted the Cuvée Originel bottling of 2014, for its 35% Pinot Blanc of course; interested to learn how such a Forgotten Four lead, with the three Usual Suspects trailing, would work out.
‘Splendidly’ is the answer.
The gold is striking, the nose is suitably complex. One gets mint, cucumber, cornichon tartness (I mean, the true kind of https://www.kesbeke.nl/) and some olive.
On the palate, it switches to agrumes-allsorts. Yuzu, lightly pre-ripened apricot (yes there’s acidity in there), sparkling grape (ah.) and a hint of almond already. This slowly develops into lemon-grapefruit on the one hand, and yellow curry / pineapple on the other, with a tangerine almost orange'y element integrating both sides. I’d say, there’s a marbling of mirabelle (in Dutch: https://maverisk.nl/mirabelle-wil-iedereen-welle/) running through it as well.
‘But’ overall it certainly is far from flubby (the 3g dosage having turned into the above, no sirup) or acidic. The quality of it all, and the light oak touch, twist all the richness back towards the freshness of citrus zest. And did I mention the mousse is still there, slowly releasing?
Towards the lingering finish, this all persists in a extremely well-balanced acidity and a hint of minerality and sophisticated bitterness.
Am I happy to have another one of these standing ready
Marie Courtin Présence
I bought the @ch_mariecourtin for the 1/3 Pinot Blanc (of course: https://tinyurl.com/ForgotFour !). High expectations, exceeded.
First off, the yellow-golden almost amber colour would promise some sweet almost creamy elements. But with a delightfully tingle from a fresh mousse, and a light bitter-tartness in the nose, the picture turns around completely. There’s Mirabelle ..! [As per: https://tinyurl.com/Mirabellepg]
The palate is perfect; not too much mousse so the real ‘wine’ taste is clear, and the Mirabelle keeps on coming. The mouth feel overall is well-balanced, and includes a soft minty/dill side with the lemon (plus some bittersweet orange even), moving into the grapefruit area and then the mirabelle’s back again. The very long finish has the mint/dill combo again, and an inkling of sugar. But with zero dosage, that’ll be the Chard and almost certainly the Pinot Blanc waving goodbye. Throughout, there’s a slight undertow of pickled cornichon (Amsterdam style; what else?)
All in all, it’s a wonderful demo of what Pinot Blanc can bring; lifting the Chard from its average whilst pulling itself up into high performance. Merging the best of both into Something Else of a great wine. This being a zero dosage, zero sulphur added, zero intervention wine, it also proves that ‘natural’ wines need not be f(l)unky. But on the contrary, one would hardly be able to tell.
The Présence is course material in so many ways. Am I happy? Well, not with six other dwarfs but yes, very much so.
The @champagne_gruet Cuvée Arbane …
𝘚𝘰𝘮𝘦𝘵𝘩𝘪𝘯𝘨 𝘌𝘭𝘴𝘦 entirely!
100% Arbane yes. Which brings a freshness too long lost. Reminds me of the bone dry styles of yesteryear, in a good, rather great way. Chalky without dust, minerality without flint. A wonderful conversation starter, on the good things of life.
With a fresh and quite light, lemon-white colour through which a very fine and persistent mousse promises delight. Then, on the nose, one gets a first whiff of floral notes; jasmine, elderberry, rose – followed by zingy but ripe lemon. When allowed to mellow in the glass (or a day in the bottle), the lemon slowly brings along some grapefruit, pineapple and (dry white) melon. All within measure, refined, nowhere too in-your-face’y.
The mouthfeel is brilliant with the mousse playing its role to keep the very well balanced aspects all quite light. The dosage is hardly noticeable – from the taste of it, one would estimate 2g. max, and notes of soft white peach, light albedo, with a very long finish on the thyme/mint/dill spectrum with the albedo bitters lingering on.
Would work miraculously with e.g., flounder with serious sauce and herbs, swordfish with almond crusting, maybe tuna or mackerel, or white meat.
Saw a score somewhere of 91/100, but that's too low.
Buxeuil doesn’t have any Arbane of its own (in production), but with this Gruet wine, it has a flagship.
Arbane being at only 0,018% (yes, percent) of Champagne’s acreage, this cuvée highlights the 'need' (want!) for quite an extension of that.
Tasting the Pinot Blanc champagne of Gruet of Buxeuil (@champagne_gruet). That’s right, a pure-bred PB champagne. (Be sure to pick the right one, at https://www.champagne-gruet.com/)
And it is a treat, indeed.
In the glass, we have a very fine mousse, well-integrated - it continues very, very long and doesn’t just give a one-off foam layer – through a pale gold, slightly varietal-typical PB wine.
On the nose, the typical character come through immediately, including a slightly fluffy air of white flowers around light tangerine / (white) peach / mirabelle, and a core of lime – keeping nicely short of being bitter.
The mouthfeel is light, but not fleeting. One gets beautiful straight near-ripe lemon, a waft of mint with white blossom, and some white pepper towards the back. Add to that lemon white skin with edges of red grapefruit.
Mind you; I had kept some for a second tasting, and four days (suitably cool storage) after opening, all this was still as fresh. No ‘dosage plays up after too much air’ or so; great.
A top recommendation, this one. If only to keep the Forgotten Four Cépages alive, as they deserve, but also for sheer tasting pleasure. Or ‘the trick one’ at a tasting experiment. Or for an apéritif or with whitish seafood (if not to lime’y or salty).
The Réminiscence 100% pinot blanc brut nature by @champagneericlegrand via @jeromeschampagne. Supposedly off 65+yr old vines, but one would be hard-pressed to tell that by the wine. What delicious freshness!
For a start: What would one expect from a pure PB champagne? Subtlety indeed.
It starts with a new capsule (for me, to further fill my https://www.deknudtframes.fr/en/catalog/product/s65sz2-/frame-in-black-for-champagne-caps which only applies to *different* capsules I tasted *at home*) – under a muselet to duly impress. After a good whiff, one can immediately pick up the something-different of this one. The first 80% is most clearly artichoke with some mint; not very strange since we just made such a dip for (neutral) crackers five minutes before.
After which, with careful nosing/tasting, we get a white-floral element with traces of almonds and yes even a hint of vanilla and the slightest of dried yellow fruit. This continues in the long developing taste, clearly adding ‘a point’+ ripe lemon (citron), with the etheric element slowly (very slowly) fizzling out. Can I say ‘retronasally’ there? As it tactilely *feels* that way for sure. Add some vanilla points in the long after.
All in all, a thing to be savoured. And, let’s promote these ‘forgotten four’ champagnes! Away with the factory work! (One suspects the 24x range by some famous grand marque points in the right away direction, too, qua hyper-mass production orientation.) The more sure we have of being able to choose to never have to taste a same champagne ever again in one’s lifetime. *If* one would want to – wines like the Réminiscence make one still would want to return often. Extend the plantation!
Another round for Gruet of Buxeuil (@champagne_gruet) – The Cuvée des 3 Blancs (as here)
With its matte gold, almost amber appearance and very fine mousse (hardly foamy but lingering in the mouth for a long, long time), we'd expect the Pinot Blanc to dominate over the Arbane and even Chard. It does. A little. But, as assemblages go, only a little; I'd rather say one can identify the PB by its gently soft but full agrumes/mirabelle character but there's a lot of exquisite light flowers – hawthorn – and herb'iness – in the sage, rosemary corner – already in the aromas. Would that be the continuum of the Arbane and Chard?
If one would want to take it analytically.
Savouring, one would enjoy the all-round calm structure, with a medium to full mouthfeel (nothing sticky). And just the image (?) of a surprisingly light white wine with lots of mature grapefruit, lemon and a slice of lime. From which the little bitter note lingers on in the back, most pleasantly refreshing, nothing astringent or harsh. Overall, certainly not chalky bone dry but a hint of mango.
Would I pair this all with food ..? That would be a. hard; a very careful cheese selection might do, b. interesting, to see where the flavours go (see below), c. not necessary, it's a wonderful treat on its own.
This, in a series of Forgotten Four tastings, as per this 'research'.
And the (aubépine and) mirabelle note, Gruet themselves also list. Nice, yet another example of that great aroma.
Plus, one of course has e.g., this and this book, or quite a few others, already..?
Of boek. Hoewel er een beperkt aantal boeken is dat ik hoog heb, zit er niet een[1] bij die nou net op het onderdeel dat mij respectievelijk interesseert, het α tot en met ω heeft. Waar-om en waardoor ik juist de verdere research wil/ 'moet' doen...
[1] Nou ja, deze komt in de buurt...
Jazeker! Zoveel is zeker: Voor bijvoorbeeld de Fransen is dat een volstrekt normale karakterisering. Het gaat dus niet om NaCl uit een Jozo-vaatje... Eerder "off-vuursteen"; denk ook aan de regio van hints in de verte bij wit-peperigheid en magnesium in de buurt. Niet vreemd, als oesters zeer rijk zijn aan zink (sic), ijzer, calcium (dûh) en selenium. Sommigen in NL zeggen dan dat je geen 'zout' of zelfs maar 'zilt' mag zeggen. 1. Van wie niet ..!? 2. Waarom niet ..!? 3. Dat is toch voor zéér velen de beste karakterisering – niemand beweert dus dat er keukenzout in uw wijn zit en iedereen weten dat de karakterisering losstaat van enige bewering van objectieve chemische samenstelling anders zouden we wijnaroma's héél anders beschrijven!
Of zelfs Philpatrick het moet niet gekker worden ... Dus denk niet dat de spellcheck op hol sloeg.
De Cuvée Métisse, noirs et blancs oftewel 80% PN en, jawel, 20% Pinot Blanc, wederom een assemblage met een van de Forgotten Four. Brut nature dat houdt het puur, klaargemaakt bij de BV Val du Clos dan nemen we ook een verre hint daarvan mee. Van Champagne Olivier Horiot, MeB juli 2020, dégorge 16 jan 2023, grotendeels oogst 2019 plus nog een scheut uit de Réserve Perpétuelle die op eik wordt gehouden – ja ik kwam 'm in een coin oublié tegen maar prijs me gelukkig. Quelle belle ouvrage! Als u denkt: Da's een nogal technisch verhaal – dan is dat juist maar het proeven is gewoon een onbekommerd plezier. Het begint uiteraard met de sprankelende licht-amber kleur en een neus met het lichte bittertje, denk aan het dille-thijm spectrum, van de Blanc. Terwijl dan de eerste smaak van de Noir komt. Hoewel licht door de jaren, en dat pufje bitter komt er snel weer bij. Rijpe-appelzuur, heel lang gematigd door-coastend verdund citroensap met in de verte mango en met witte zest erboven zwevend. Maar wel in complete balans, niet vlak of zo maar juist met transparante diepte. Toen ik er een hapje net-nog-niet-compleet-rijpe ananas(kern) bij nam, was dat een moeiteloze, zowat volledige overlap. Later komt er een onderstroom(pje) van iets dat neigt naar kruiden door de mond. En nog steeds met zeer fijne bulles, by the way; verfrissend zonder prikje. In termen van verwachte aroma's zou ik eerder tussen Chard en Meunier op pad gaan van jong naar iets voorbij het midden, en zeker niet te ver naar de rijpe complexe PN-hoek zakken. Al met al een 'opulente' wijn die verrassend jong van geest is (gebleven). De PN is meer steun dan leider in het geheel; prima! En de PB viert z'n vrijheid om te shinen; uitstekende reclame!
5 Sens: De Oogst-2017, MiB 24 juli 2018, Dégorge 12 mei 2023 ja zo exact, met nul dosage voor slechts 1320 fles plus 90 magnums. Van 5 verschillende terroirs, oude stokken van 5 verschillende cépages – PN, Chard en Meuier, en dus ook Arbane en Pinot Blanc; langzaam vergist en opvoeding sur lies. Dat geeft volgens de makers de vijf (jawel) elementen Water, Aarde, Luchten Vuur – en l'Esprit! Wederom een assemblage dus van Olivier Horiot (op @horiotolivier) met Forgotten Four, klaargemaakt bij de BV Val du Clos dan nemen we ook een verre hint daarvan mee. Zo, dan heeft u de data gehad. In termen van aroma's als op de vaste plaat gaat het alle kanten heen, waarbij we ook (laten we zeggen 'traditionele') Chard- en PN-aroma's tegenkomen. Maar niet te uitdrukkelijk. Om het op een rijtje te zetten: De kleur is vol maar licht goud; De mousse is heerlijk, (nog) ruimschoots aanwezig maar zeer fijn; In de neus krijgen we eerst rozenblaadjes en een tikkie mango, maar zo nu en dan ook een zweem ziltigheid ..? Een ander zou het ook witte-peperigheid kunnen noemen. Sommigen vinden dat Arbane meidoorn en anjer geeft; nou ja dat kan ik begrijpen maar pikte ik niet op. Noch wat appel en kweepeer, dat gewicht trof ik minder: Het volle mondgevoel zit stevig in de citrus-hoek. Denk aan lauwwarme, (over)rijpe citroen met een beetje suikerrijpe peer en (geblancheerde) ananas, op het mirabelle af maar wel met een los zwevend zuurtje dat eronderdoorlangs komt zweven, inclusief een puntje venkel/dille. Ik denk dat hier vooral de wat rijpere Pinot Blanc om de hoek komt kijken. Maar al met al wordt het nergens te zwaar; de wijn blijft gewoon helemaal in balans; De citroen is de core der (talrijke) caudalies; zelfbewust maar niet zwaar. Nou ja, als eindconclusie; deze zit op het niveau van een lichte montbazillac of sauternes met mousse..! Werkelijk heerlijk. Voor zover er wat bij moet worden gehapt, zou ik zeggen: Niet te licht, niet te dicht op de sla/Brillat-Savarin-hoek, of te kale zilte oesters. Eerder oesters met enige bewerking, zou ik zeggen. Als per deze – en een geel- of roodschimmelkaasje kan ook nog prima. (vandaar; lichte sauternes ...) – oh en een salade met cajunkip kan ook ...
![]()
Étoiles du Nord, voor uw betere wijnen...
Al is het alleen maar door Il Respiro del Vino te kunnen lezen; geen vertaling tot nu toe dan maar zwoegen.
Le Chardonnay rose est une mutation du Chardonnay blanc que l’on trouve historiquement à l'état de ceps isolés dans les vignobles champenois et bourguignons. La mutation porte principalement sur la couleur de la baie qui est d’un rose foncé à maturité. Cette différence a abouti à la proposition d’individualiser le Chardonnay rose comme une variété distincte de sa forme blanche et de l’inscrire en tant que telle au Catalogue français.

L’origine de ce cépage est difficile à dater. Néanmoins, il existe quelques repères comme la date de son introduction dans la collection de Vassal-Montpellier en 1950 ; deux accessions (ou "introduction" est un clone non agréé conservé dans une collection) de Chardonnay rose y ont été plantées cette année-là. La première, issue de l'ancienne collection dite "de Ravaz" de l'Ecole de Montpellier (donc la date réelle est antérieure à 1950), provenait initialement de la Côte d'Or. La deuxième provenait de la "collection Couvreur Pernin", à Rilly-la-Montagne dans la Marne.
Depuis peu, le Domaine de Vassal-Montpellier possède également deux accessions assainies issues du clone de Rilly-la-Montagne. Récemment de nouvelles accessions de Chardonnay rose ont été recensées dans le vignoble champenois, preuve d’un intérêt croissant pour ce cépage ancien. Cependant, la disparition progressive des veilles vignes ainsi que la pression croissante des viroses, faisaient craindre la perte de diversité génétique au sein de ce cépage et l’abandon de sa culture.
Zie deze voor andere benamingen bij een andere leverancier.